
Fiabilité et conformité : la donnée devient un véritable défi pour les institutions financières
Au cœur des institutions financières, la qualité des données est devenue aujourd’hui un sujet à double enjeux : fiabilité de l’information d’une part et conformité réglementaire d’autre part.
En effet, sur le premier aspect, une donnée de mauvaise qualité engendre des coûts considérables, et une conduite opérationnelle efficace demande des informations fiables pour un pilotage avisé. Sur le deuxième aspect, la réglementation cadre de plus en plus le métier, par exemple par les normes BCBS 239 qui sont en vigueur en ce moment. Cependant il n’existe pas à notre connaissance d’approche ou de méthodologies standardisées permettant de répondre à ces enjeux de manière efficace.
On peut, d’une certaine manière, identifier deux problématiques liées à la qualité de la donnée : la première, qui demande une compétence métier, consiste à déterminer si une donnée, calculée (par une application) ou exogène (provenant d’une source d’alimentation externe à l’application), est acceptable ou non (BCBS 239 : processus, outils et dispositif d’évaluation des données). Une fois une anomalie détectée, le deuxième sujet consiste à identifier la cause de l’anomalie pour une action éventuelle (BCBS 239 : Auditabilité et traçabilité des données).Cette étape est parfois difficile, et très souvent consommateur en temps, notamment dans les systèmes d’information (SI) de grande taille, ou il est particulièrement délicat de savoir si l’anomalie provient d’une erreur interne provenant de la logique applicative, ou d’une erreur externe provenant de l’alimentation en données des applications.
Cet article propose une approche permettant d’aborder ces problématiques de manière systématique. L’idée est simple : la qualité de la donnée est intimement liée à la connaissance précise du système d’information qui l’a produite. Nous proposons d’utiliser une nouvelle technologie permettant en théorie la cartographie automatique, partielle ou intégrale, d’un système d’information, ce qui peut d’ailleurs au passage faciliter grandement son urbanisation. Cette connaissance fine du système d’information permet notamment d’envisager une détection et une analyse efficace des anomalies dans la production des données : elle permet de tracer toutes les étapes de la production applicative, de la donnée en entrée jusqu’à celle en sortie, en passant par l’algorithme qui l’a produite. Cela permet d’envisager des systèmes ou algorithmes semi-automatique d’analyse d’anomalies, proposant de compléter les outils de contrôle ou dispositifs de conformité de la donnée, si ceux-ci s’avèrent insuffisants, et in fine d’intervenir pour correction si l’origine du problème est suffisamment circonscrite et identifiée.
MPG Partners propose de mettre en place cette nouvelle technologie. D’un point de vue technique, nous nous reposons sur deux concepts : le premier est la notion de graphe. Le deuxième consiste en les propriétés d’introspection des langages de programmation modernes. Les notions d’introspection permettent de cartographier dynamiquement l’algorithme d’une application ou d’un système d’information, tandis que la notion de graphe permet de tracer la production de la donnée. Nous utiliserons cette implémentation pour illustrer cette méthode par un exemple, la détection et l’analyse d’une anomalie dans un moteur de VAR (Value-At-Risk), souvent utilisé pour la mesure des risques de marché.
L’implémentation utilisée dans ce papier repose sur des technologies XML standards, ce qui a l’avantage d’être le format requis par le régulateur. La notion de bases de données graphe y a été implémentée dans un produit que nous appelons XQUERY++. Il existe des bases de données graphe (e.g. NEO4J, ou MongoDB en open source), cependant, aucune ne repose sur des technologies XML standardisées. Nous avons également développé des outils sur la base des capacités d’introspection du langage XQUERY, permettant de suivre la production de la donnée.
Comment fonctionne cette technologie innovante ?
La notion de graphe pour les données et les algorithmes
La notion de graphe est une notion naturelle et universelle pour la représentation des données. Par exemple, une ligne dans une base de données SQL peut-être vue comme un nœud, pointant vers les différents enregistrements qui sont autant de nœuds contenant des données élémentaires. Les bases de données relationnelles utilisent la notion de jointure pour exprimer les liens (ou arêtes) entre les données. De la même manière, un fragment XML représente une donnée sous forme d’arbre hiérarchique, ce qui est une structure de graphe particulière.
De notre point de vue, la représentation sous forme de graphe est un point commun à toutes les représentations fonctionnelles des données (telle que spécifiée par une maîtrise d’ouvrage), et surtout ne s’applique pas qu’aux données, mais également aux algorithmes et applications.
En effet, une fonction peut toujours être interprétée comme une suite d’exécution séquentielle d’opérations plus ou moins élémentaires. Dans cette interprétation, cette fonction peut-être également interprétée comme un graphe « d’exécution » : on représente la fonction comme un nœud, avec un lien entrant vers l’ensemble des données en entrée, et un lien sortant vers les données que cette fonction produit. Cela correspond à une vision « fonctionnelle » (par opposition à « impératif ») de la programmation.
De manière similaire, une application, quelle qu’elle soit, peut-être vue comme une collection de fonctions exécutées séquentiellement. En utilisant la représentation précédente, un programme informatique forme un graphe connectant toutes les données dont il a besoin en entrée aux données qu’il produit. Les fonctions étant alors autant de nœuds permettant de les connecter. C’est d’ailleurs ce principe qu’utilisent les débuggeurs, qui permettent de tracer l’arbre d’exécution d’une application.
Enfin au dernier étage, le SI d’une entreprise est une collection d’applications échangeant des informations. La représentation précédente permet de visualiser le système d’information d’une entreprise comme un graphe, augmenté en permanence par la production de la donnée et évoluant au gré des refontes et maintenances diverses.
Cette représentation sous forme de graphe possède un autre mérite : celui de définir clairement la notion de granularité. Pour rendre le propos moins abstrait, considérons un exemple applicatif.
Illustration pour le calcul d’une VaR en sensibilité
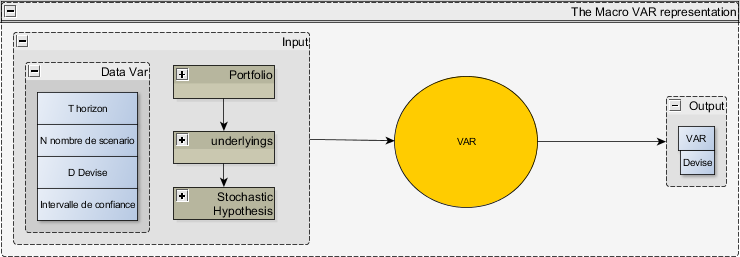
On décrit dans ce paragraphe une application que nous avons traitée : la VaR (Value At Risk) est une mesure permettant d’estimer les pertes potentielles d’un portefeuille donné avec un niveau de confiance déterminé et à un horizon de temps donné. Il n’est pas utile de comprendre le détail fonctionnel de cette application pour comprendre le propos de cet article. Il suffit de concevoir que la Figure 1 représente une application sous forme de graphe élémentaire. La même application est représentée de manière plus détaillée dans la Figure 2.
La fonction VaR – représentation fonctionnelle – granularité faible
Dans ce paragraphe, on représente ce module de VaR au niveau de granularité la plus faible, i.e. en décrivant ce dispositif comme une unique fonction, ayant en entrée :
- L’horizon T, l’intervalle de confiance X, la devise D, le nombre de scenario N
- Une liste de J sous-jacent, dénotée (S1,…Sj)
- Un portefeuille, contenant une liste de produits dont on connaît chaque valorisation dénotée (P1,…PI) dans la devise D, ainsi que les sensibilités Pj, i= 1..I, j = 1…J. On notera la valorisation globale du portefeuille.
- Une liste d’hypothèses stochastiques, précisant le processus stochastique sur chaque sous jacents.
En sortie, la fonction génère
- Un nombre et une référence vers la devise, la VAR, correspondant à la probabilité de perte à X%.
Le diagramme suivant illustre cette fonction
Figure 1 - Représentation macro de la fonction VAR
La fonction VaR- représentation fonctionnelle – granularité plus forte
Le calcul de la VaR est composé bien sûr d’étapes intermédiaires, qui font partie de l’algorithme de la fonction. Cet algorithme est décrit plus finement par les étapes suivantes :
- Valoriser le portefeuille. Il s’agit simplement de la somme P1+…+PQ
- Calculer les sensibilités du portefeuilledP/dSi. On appelle cette fonction GetSensitivities. Cette fonction est décrite par les étapes suivantes : pour chaque produit
- Identifier ses sous-jacents (GetUnderlyings)
- Récupérer les sensibilités sur chaque sous-jacent (GetSensitivities) dPj/ dSi
- Agréger par sous-jacent dP/dSj
- Générer les scenari (fonction GenerateScenario). Cette fonction
- Liste les sous-jacents du portefeuille
- Génère N scenari sur chacun de ces sous-jacent, Sc1,..,ScN, à l’horizon T
- Calculer le PNL sur chaque scenari, par sensibilité. Pour cela
- Sur chacun des N scenario, on génère un vecteur de sous-jacent dénoté S_^n (T):=〖(S_j^n (T) )〗_(j=1..J).On calcule par approximation au premier ordreP (T,S_^n (T))=P(0)+∇P(0) .(S^n (T)-S_0 )
ou on a noté le vecteur ∇P(0)= (∂P/(∂S_j ))_(i=1..J) le vecteur des sensibilités.
- Sur chacun des N scenario, on génère un vecteur de sous-jacent dénoté S_^n (T):=〖(S_j^n (T) )〗_(j=1..J).On calcule par approximation au premier ordreP (T,S_^n (T))=P(0)+∇P(0) .(S^n (T)-S_0 )
- Sortir la VAR. Cela correspond à
- Classer par ordre croissant la suite (( P(T,Sc_1 ),..,P(T,Sc_N ))
- Identifier le scenario à l’intervalle de confiance, noté k.
Le diagramme suivant illustre sous forme de graphe l’algorithme de calcul de VaR décrit ci-dessus.
Figure 2 – Fonction VAR détaillée
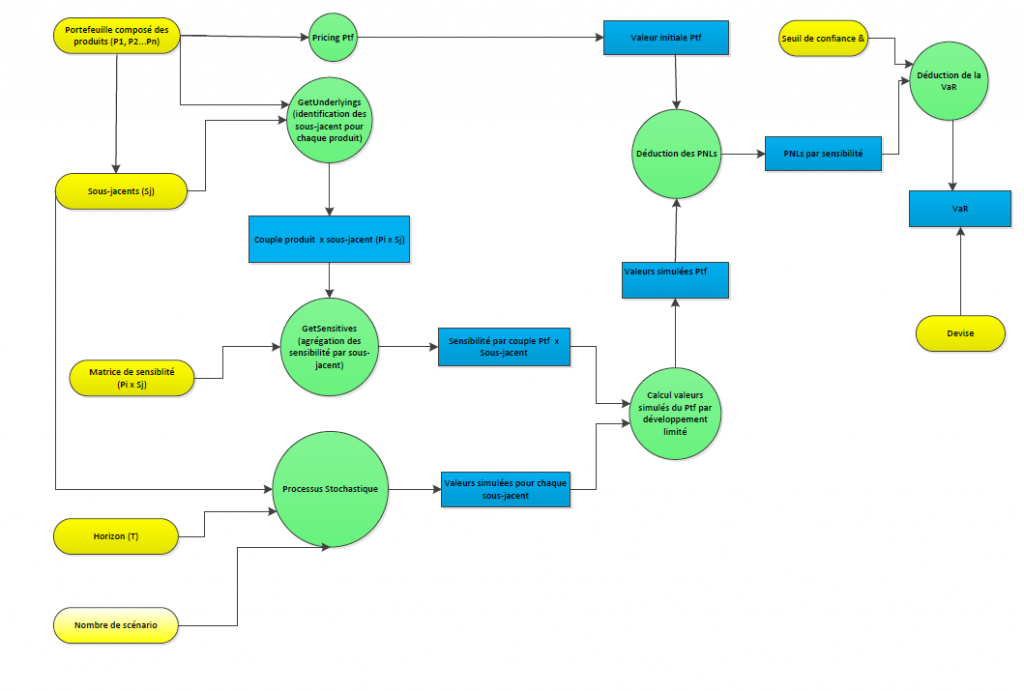
Ce diagramme fonctionnel est ainsi une représentation plus précise que celui présenté Figure 1 – Représentation macro de la fonction VAR.
Représentation technique des données
Les données sont représentées sous forme XML, avec des notations type graphe. Par exemple, prenons l’exemple d’une donnée type « StochasticHypothesis », donnée que l’on voit apparaître en entrée de la Figure 1.
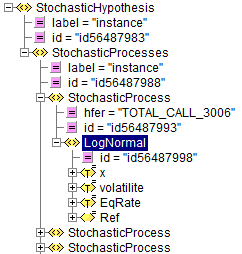
On remarque que :
- Toutes les données sont identifiées de manière unique – par un attribut id.
- La notion « hfer » signifie que le graphe définit une arête entrante, de la donnée dont l’identifiant est « TOTAL_CALL_3006 », vers la donnée pointée, qui est la donnée d’identifiant est «id56487998 « . De la même manière, les liens sortants sont notés par un attribut, « href ».
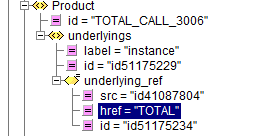
Par exemple, voici la représentation XML du produit TOTAL_CALL_3006, qui porte un lien sortant « href » vers l’action TOTAL.
Représentation technique des algorithmes
XQUERY++ est écrit dans un langage, XQUERY, qui possède de très bonnes propriétés d’introspection. Notamment, ce langage peut répertorier l’ensemble de ses fonctions en début d’exécution. Cela nous permet par exemple de décider de logguer les résultats d’une ou plusieurs fonctions par un fichier de paramétrage.
Prenons par exemple les résultats du log résultant de l’exécution d’une fonction, la fonction « déduction des PNL » de la figure 1, qui est appelée NPV dans le programme de calcul. Cette fonction calcule le PNL de chaque position. Il s’agit simplement de multiplier une quantité par une valeur unitaire, qui est celle de l’instrument sous-jacent.
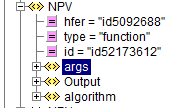
- Le log de cette fonction possède, comme le sont les données, un identifiant unique id= »id52173618″
- On repère qu’il s’agit d’un log de fonction par l’attribut type= »function »
- Elle a été appelée par la fonction dont l’identifiant est « id5092688 »
- Elle possède des arguments en entrée décrits dans la section<args>
- Elle a produit en sortie des données décrites dans la section <Output>
- Pour produire ces données, elle a exécuté un algorithme décrit dans la section <algorithm>
Par exemple, la section algorithme est décrite par le fragment XML suivant
Figure 3
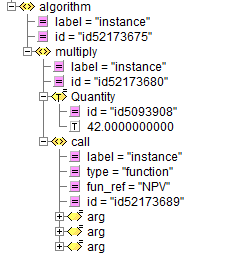
Qui décrit l’algorithme de calcul de la fonction NPV pour cet appel : il s’agit de multiplier la quantité 42 par le résultat d’un appel à une autre fonction NPV, l’instrument étant en fait un panier de trois autres positions.
On voit par cet exemple comment les propriétés de log permettent former un graphe d’exécution connectant les données en entrées aux données en sortie. Le graphe sera plus ou moins complet suivant le degré de granularité choisi par le paramétrage du log. Cela permet de tracer tout ou partie de l’algorithmie propre à une application.
Détection des anomalies : un algorithme efficace
Dans ce paragraphe, imaginons que l’on a à disposition un « dispositif de conformité », i.e. un programme capable de détecter une anomalie dans une donnée produite par une application ou une fonction.
Par exemple, reprenons la Figure 1 – Représentation macro de la fonction VAR. Celle-ci peut-être logué, voici le résultat du log :
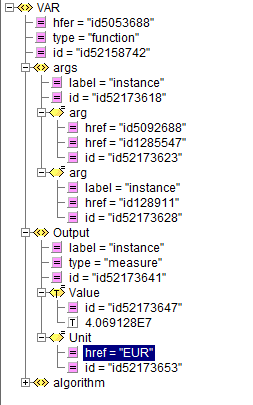
La fonction VAR a calculé une valeur de 4069128 EUR. Le dispositif de conformité détecte que cette valeur est mauvaise. En inspectant ce log, il peut déterminer automatiquement que le problème provient :
- Soit des données décrites dans la section <args>, qui décrivent deux types d’input : les données importées (référencées par href= »id1285547″, un conteneur vers les données « Portfolio », « Underlyings », « StochasticHypothesis » de la Figure 1 – Représentation macro de la fonction VAR), et les données de paramétrage de l’application (référencées par href= »id1285547″, contenant les variables N,T,D,I).
- Soit en inspectant l’exécution de l’algorithme décrit dans la section <algorithm> : la Figure 3 proposant un exemple du contenu de cette section, qui correspond à l’algorithme décrit dans la description fonctionnelle Figure 2 – Fonction VAR détaillée.
La prochaine étape du « dispositif de conformité » sera d’inspecter chacun de ces deux branches pour déterminer l’origine de l’erreur. Inspectons chacune de ces branches pour déterminer un algorithme permettant de détecter la cause de l’anomalie:
Concernant les données en entrée, il y a plusieurs possibilités :
- Le dispositif de conformité ne sait pas déterminer si ces données sont conformes ou pas. Une assistance humaine est alors requise pour lever l’ambigüité et idéalement enrichir le dispositif de conformité.
- Le dispositif de conformité sait déterminer la validité de ces données.
Si elles ne sont pas valides, la prochaine étape de l’algorithme sera d’inspecter les fonctions qui ont produites ces données. L’algorithme peut notamment ici décider automatiquement de tracer les fonctions correspondantes pour la prochaine exécution.
Si ces données sont valides, le problème provient de l’exécution de l’algorithme de la fonction. Il n’est alors pas nécessaire de remonter plus avant, le problème se trouve dans la section algorithmique de la fonction.
Concernant la partie algorithmique, il y a plusieurs possibilités :
- Soit cette partie n’est pas décrite. En effet, on peut supposer que par défaut toute l’exécution de l’application n’est pas logguée, pour éviter de produire des quantités de données considérables et difficiles à traiter. Auquel cas le dispositif de conformité peut décider de logguer cette partie à la prochaine exécution.
- Soit cette partie est loguée, auquel cas il s’agit d’une collection d’appels à des fonctions dont le log est identique à celui de la Figure 3, et pour lequel la méthode décrite dans ce paragraphe s’applique pour déterminer leur conformité.
On voit que cet « algorithme de conformité », relativement simple à mettre en œuvre, permet de remonter à la source de l’erreur progressivement.
Conclusions et mise en œuvre opérationnelle
Dans l’exemple applicatif de cet article, nous avons démontré comment, en utilisant des fonctions d’introspection avancées des langages et la notion de graphe, il est possible de cartographier l’ensemble d’un système d’information, à n’importe quel niveau de granularité, et de manière dynamique.
Cette cartographie peut ainsi être utilisée pour tracer l’ensemble des fonctions et résultats intermédiaires responsables de la production d’une donnée. Couplé à un dispositif de conformité, cette méthodologie permet de développer des outils et algorithmes favorisant la détection de la cause d’une anomalie.
Ce type de dispositif pourrait être déployé pour répondre efficacement aux problématiques soulevées dans l’introduction : qualité de la donnée, fiabilité applicative, et coûts associés. Cela permettrait également de poser les bases d’une urbanisation harmonieuse et efficace des systèmes d’information, condition essentielle pour les métiers de l’assurance et de la banque.
Par ailleurs, cette nouvelle technologie s’intègre rapidement dans les SI existants, particulièrement dans le cadre de la mise en place de nouvelles applications, mais également de maintenance / évolutions planifiées de l’existant. En outre, couplée avec l’expertise méthodologique de MPG Partners, la technologie innovante XQUERY++, peut-être rapidement déployée pour résoudre des problématiques parfois très complexes (production du COREP par exemple).
Nous concluons cet article par une réflexion et une mise en perspective de la réglementation, comme l’est par exemple la norme BCBS 239. On a vu dans cet article qu’une mise en œuvre moderne et efficace de cette norme demande le développement de techniques informatiques innovantes. Notamment, on peut penser que ces normes règlementaires devraient être proposées conjointement avec le développement de normes informatiques adaptées. Par exemple, les idées développées dans cet article pourraient servir comme base de réflexion pour spécifier des normes de langages informatiques, pourquoi pas conjointement avec l’aide d organismes de standardisation informatiques, comme le W3C.
